


Linear Language Models and their Memory Limitations
Abstract
Transformers (Vaswani et al.) and their instances (e.g., GPT) have shown strong performance using self-attention and masked attention. However, their quadratic time complexity limits generalization over long sequences. We evaluate the associative memory capacity of sequence decoders with different internal mechanisms, replacing standard attention with linear and recurrent layers, inspired by RNNs.
This research project was undertaken for the class “AI Center Projects in Machine Learning Research” at ETH.
Implementation
We implemented six architectures: LSTM, quasi-LSTM, LRU, Linear Transformer, GPT, DeltaNet, and Mamba, and replaced the standard self-attention layer of a generic decoder with each of these architectures.
We implemented several synthetic datasets, including:
Bit Parity
# Returns a 1 if there have been an odd number of ones so far
Input: 0011010
Output: 0010011
Dyck
# Returns a 1 if the parenthesis are completely balanced
Input: {[]()}[]()
Output: 0000010101
My Contributions
We all contributed equally with implementation of different models, datasets, and debugging when the models were not learning.
Results
This was an exploratory research project to understand trends and limitations. Some interesting findings are noted below.
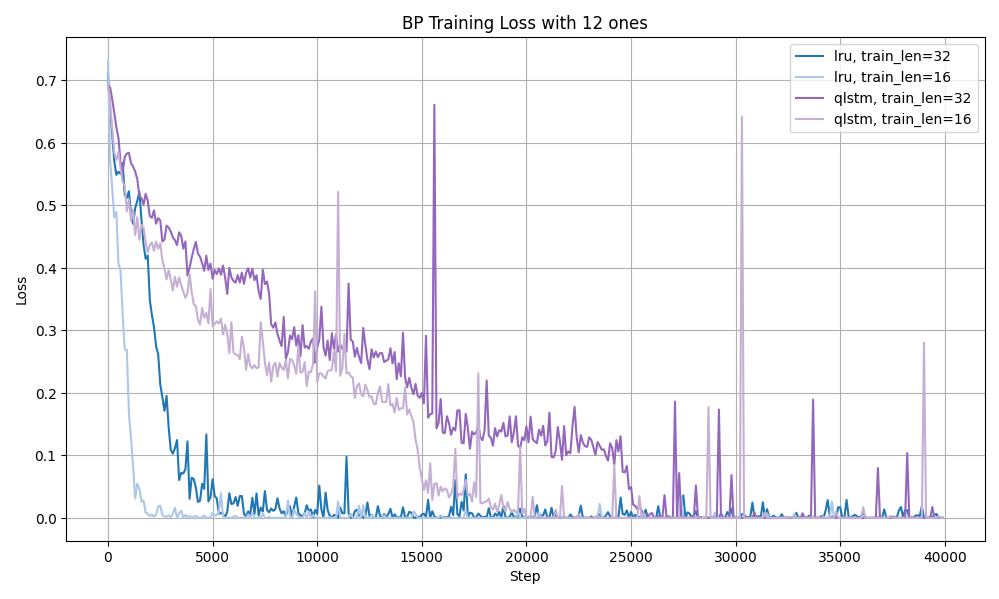
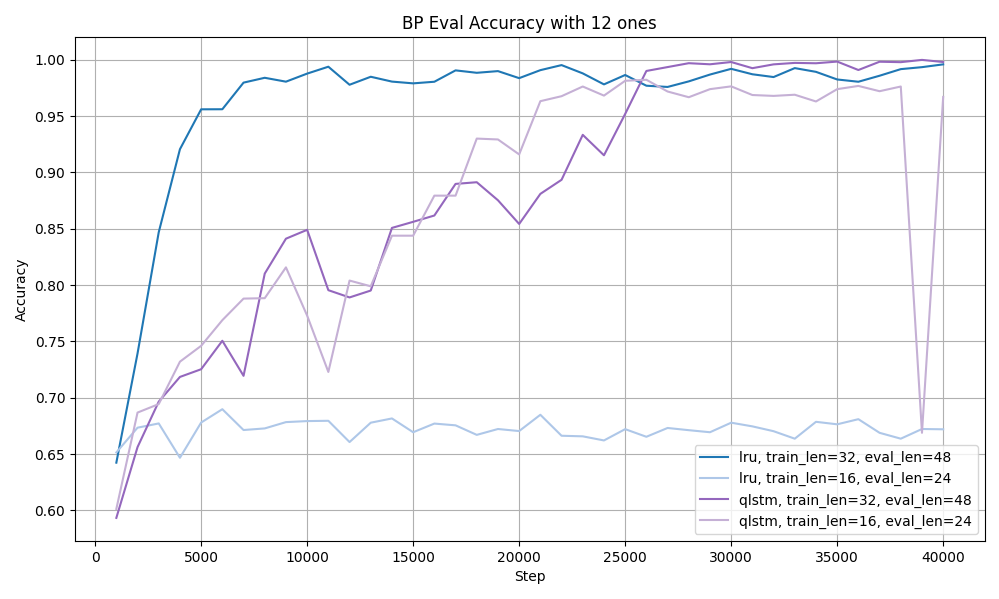
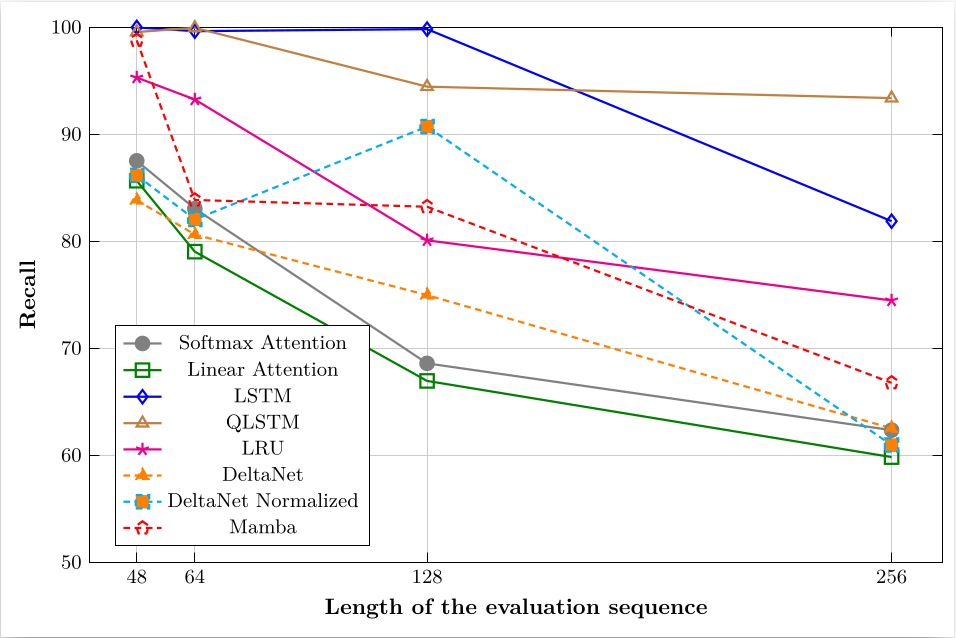
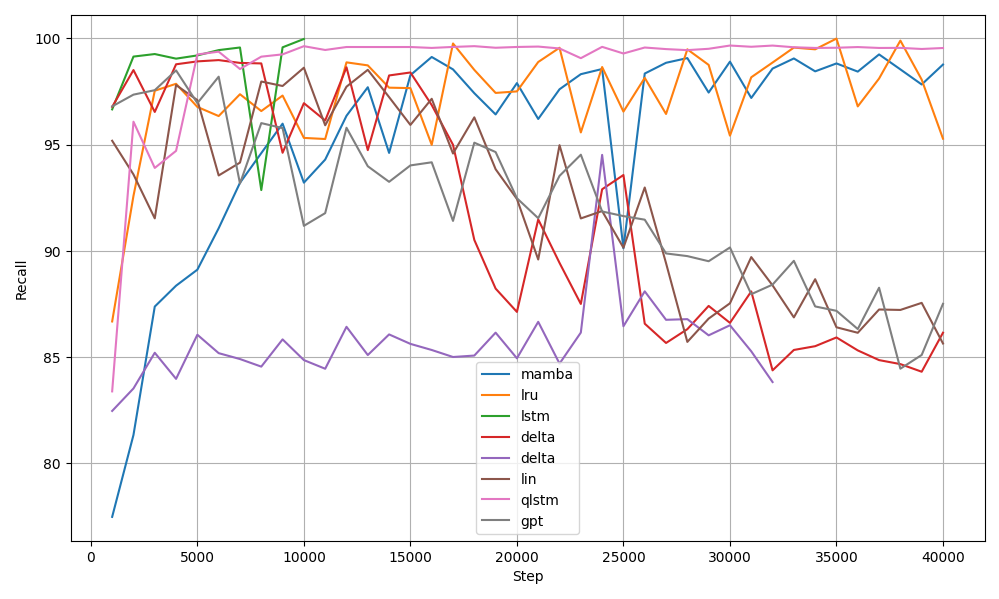
Future Work
We only had 2 months to work on this project, which was not enough time. In the future we hope to investigate:
- Performance on MQAR (Multiple Query Associative Retrieval) dataset - this is a more interesting task. We implemented it, but our models did not learn well and we were not able to discover why not.
- Explore the limited-ones Bit Parity task more to understand relative benefits and limitations of the different models.